|
My Research at Florida State University |
My research is
mainly in wireless networks, and usually involves theoretical analysis as well
as system implementations. My research sponsors include NSF and Google. I have
published in top venues such as ACM Mobihoc, ACM Mobisys, IEEE ICNP,
IEEE Infocom, IEEE/ACM
Transactions on Networking, IEEE
Transactions on Computers, and IEEE
Transactions on Information Forensics and Security. I received NSF CAREER Award in 2012, Google Research Award in 2011, and a Best Paper Award in IEEE ICC 2009. I have graduated 4 PhD students. The following is a
list of my major research projects.
Note:
1.
Unless specified as “collaborative project,” a
project involves only my students and me.
2.
Student names are shown in italic font; directly
supervised students are further marked with superscript *.
|
Fully Centralized Wireless Network based on Analog
Bloom Filter and Contention-Free Multi-Bit Simultaneous Query |
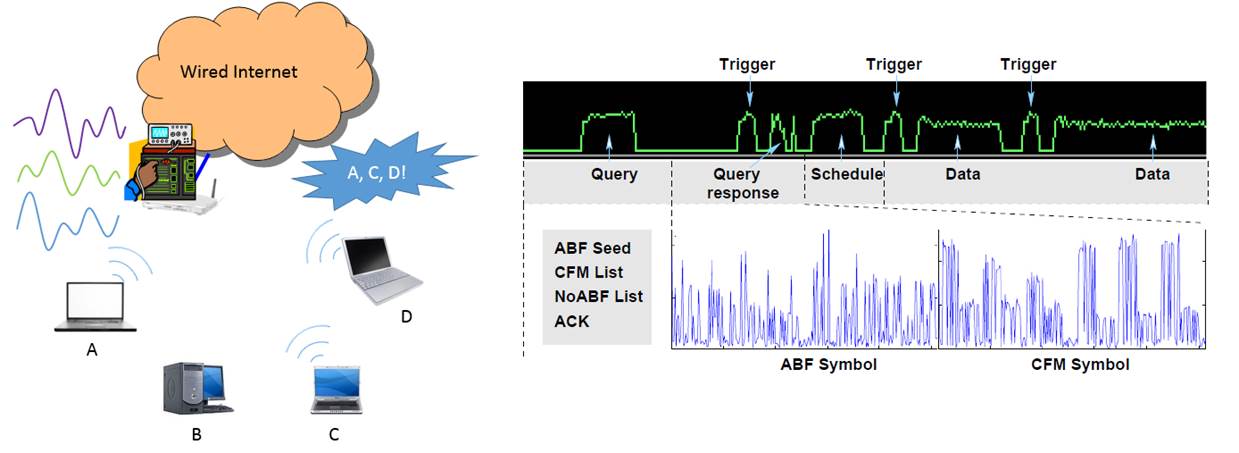
In
a typical wireless network, a base station or a router may be associated with
multiple user devices such as mobile phones.
When the network operates in a centralized manner, the base station or
the router dictates the transmission schedule, i.e., which devices should
transmit, at what time, for how long, etc. The base station or the router needs
to know the set of active devices in the network, based on which it can
calculate the data transmission schedule to meet various performance
requirements and avoid collision.
However,
learning the set of active devices may incur very high overhead. The challenge
is not with any devices that the base station or the router is currently
communicating with, because the base station or the router already knows they
are active. Instead, the main challenge is with the devices that were
previously idle and just turned active, i.e., just received data from the upper
layer. To find which devices just turned active, it is infeasible for the base
station or the router to query all devices one by one, because the number of
query messages will be large. Therefore, some random access method is typically
employed to allow the devices to inform the base station or the router.
Such
random access method faces challenges in 5G, because:
·
The number of
associated devices may be very high with the Internet of Things (IoT)
·
The latency
requirement is pushed to the 1 ms level, such that
the random access method must have overhead much less than 1 ms
Analog
Bloom Filter (ABF) is a novel solution for this problem. With ABF, the base
station or the router may periodically designate some resources, i.e., some subcarriers
in one or a few OFDM symbols. The resources are used to support a set of orthogonal
bases, such as the original OFDM subcarriers or the Zadoff-Chu
sequence modulated on the subcarriers. All
devices that just turned active may transmit signals on such resources simultaneously on multiple randomly selected bases;
all other devices remain silent. The base station or the router then runs a
demodulation algorithm to learn which devices transmitted signals in the ABF
symbol period.
The key novelty of ABF is to
allow a device to transmit multiple bases, while the current LTE solution, i.e., the LTE PRACH, allows a device
to transmit only one base. With more bases, the chance of collision loss is actually lower
when the number of associated devices is very high but the number of new active
devices is low, which is likely to be true in the 5G scenario.
The
main research challenge in ABF is to design the demodulation algorithm, such
that the base station or the router can decode the information from the ABF
signal, even when there is collision due to random base selection, without any
channel state information because the devices just turned active. The proposed
solution is based on belief propagation, and achieved good performance, such as
reducing the error ratio by more than an order of magnitude than the current
LTE PRACH.
A
version of ABF which uses the OFDM subcarriers as the bases has been
implemented on Microsoft SORA software-defined radio and has been experimentally
proven to outperform existing solutions significantly. A new Medium Access
Control (MAC) protocol is implemented based on ABF and has been shown to
achieve a MAC layer data rate more than 75% of the physical layer data rate,
even under very challenging data traffic, in which many devices alternate
between the active node and the idle mode, with many small data packets such as
40 bytes.
This research was supported by my NSF
CAREER grant: CAREER: Addressing Fundamental Challenges for Wireless Coverage
Service in the TV White Space. 1149344.
Publication:
1. Z. Zhang, “Analog Bloom Filter and Contention-Free Multi-Bit Simultaneous Query for Centralized Wireless Networks,” IEEE Transactions on Networking, vol. 25, no. 5, pp. 2916-2929, 2017.
2. Z. Zhang, “Novel PRACH scheme for 5G networks
based on Analog Bloom Filter,” to appear in IEEE Globecom
2018. Abu Dubai, UAE. IEEE
Code:
Will be made available
Slides:
Analog Bloom Filter (ABF) for Ultra-low Latency Random Access in Wireless Networks
|
CSIApx: Fast
Compression of OFDM Channel State Information with Constant Frequency
Sinusoidal Approximation |

CSIApx is
a very fast and lightweight method to compress the Channel State Information
(CSI) of Wi-Fi networks. In Wi-Fi, the CSI for an antenna pair is a vector of
complex numbers, representing the channel coefficients of the OFDM subcarriers.
The CSI is needed in many cases, such as calculating the modulation parameters
for Multi-User Multiple-Input-Multiple-Output (MU-MIMO). In Wi-Fi, the CSI is
typically measured at the receiver and is transmitted back to the sender, which
requires significant overhead. For example, on a 20 MHz channel with 64
subcarriers, the full CSI for a single antenna pair has 64 complex numbers, and
for 9 antenna pairs, 576. Although Wi-Fi does not use all subcarriers, the
feedback for 9 antenna pairs still may exceed 1000 bytes. The Wi-Fi standard
defines options to compress the CSI, such as reducing the quantization accuracy
or the number of subcarriers in the feedback, or using the Given's rotation on
the V matrix after the Singular Value Decomposition (SVD) of the CSI matrix.
However, these methods either reduce the accuracy of the CSI, or only achieve
modest compression ratios. For example, a 3 by 3 complex V matrix can only be
compressed into 6 real numbers, at a compression ratio of 3.
CSIApx is
based on an interesting discovery we made while playing with it. In short, we
found that we could approximate almost any CSI vector very well as the
linear combinations of only 5 base sinusoids, where the base sinusoids are
sinusoids on constant frequencies. In other
words, given any CSI vector, we just needed to twist the coefficients of the base
sinusoids, and we were almost always able to approximate the CSI within very
small error. After some effort, we mathematically proved the existence of such
approximations in a theorem, which states that the approximation error decays
exponentially fast as the number of base sinusoid increases.
CSIApx is
a natural application of the theorem, because it is well-known that the CSI
vector can be represented as the linear combination of sinusoids, where each
sinusoid is due to a physical a path. Traditionally, it was attempted to
reconstruct the CSI vector by finding the frequencies of the sinusoids, which
is an optimization problem with high complexity. Our key insight is that there is no need to find the frequencies of the
sinusoids, because any reasonable set of frequencies will be able to
approximate the CSI vector. In other words, as our theorem indicates, there
is a “one-size-fit-all” solution. Therefore, CSIApx uses
preselected base sinusoids to approximate the CSI, and used the coefficients of
the base sinusoids as the compressed CSI. It has very low computation overhead,
because key steps in the compression can be pre-computed due to the constant
frequencies of the base sinusoids. We extensively test CSIApx
with both experimental and synthesized Wi-Fi channel data, and the results
confirm that CSIApx can achieve very good compression
ratio with little loss of accuracy.
This research was supported by my NSF
grant: NeTS: Small: Theory and Applications of Sparse
Approximations of the Channel State Information in Wi-Fi Networks. 1618358.
Publication:
A. Mukherjee and Z. Zhang, “Fast Compression of OFDM Channel State Information with Constant Frequency Sinusoidal Approximation,” in Proc. of IEEE Globecom, Singapore, Dec. 2017. 7 pages.
Patent:
USPN Patent 9,838,104, “System and method for fast compression of OFDM channel state information (CSI) based on constant frequency sinusoidal approximation,” issued on December 5, 2017.
Slides:
Fast Compression of the OFDM Channel State Information
|
mEEC – A Novel Error Estimation Code with
Multi-Dimensional Feature |
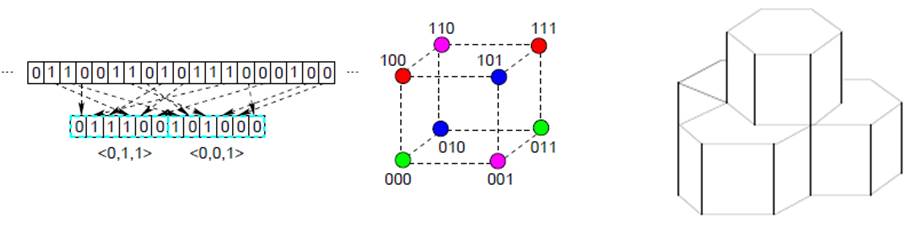
Error Estimation Code (EEC) can
be used to estimate the number of errors in a packet transmitted over a
wireless channel. Typically, such packets do not have a lot of errors, and
knowing the numbers of errors will allow the wireless transmitter to use the
most efficient method to recover the errors, such as transmitting just enough
number of parity bits, instead of retransmitting the entire packet.
EEC
typically works by taking samples
from the packet, then calculating a feature
of the samples and transmit the feature as the code. The receiver can locally
calculate the feature based on the received data packet in the same manner,
which will be different from the transmitted feature if there are errors, and
can use the difference to estimate the number of errors in the packet. The
actual EEC usually consists of multiple features calculated in the same manner.
The
main innovation of mEEC is to introduce a novel
multi-dimensional feature and a color assignment as the code, exploiting the
fact that the error ratios in partial packets are typically small. That is, mEEC divides the
sampled data bits into blocks, then groups multiple blocks into a super-block,
and uses only one number, i.e., the color,
to represent all features of the blocks. The advantage of grouping
is that it introduces useful dependencies among the blocks and allows them to
share the cost of covering low probability events.
The
evaluation shows that mEEC achieves smaller
estimation errors than the state of art on metrics such as the relative mean
squared error, on average by more than 10%-20% depending on the packet sizes,
sometimes as high as over 40%, at the same time having less bias.
This research was supported by my NSF
CAREER grant: CAREER: Addressing Fundamental Challenges for Wireless Coverage
Service in the TV White Space. 1149344.
Publication:
Z. Zhang and P. Kumar, “mEEC: A novel error estimation code with multi-dimensional feature,” in Proc. of IEEE Infocom, Atlanta, GA, May 2017. 9 pages. Acceptance rate: 20.93% (292/1395).
Code:
A Matlab implementation of mEEC can be downloaded here. Please feel free to email me for any questions related to mEEC.
Slides:
mEEC: A Novel Error Estimation Code with Multi-Dimensional Feature
|
Friendly Channel-Oblivious Jamming with Error
Amplification for Wireless Networks |
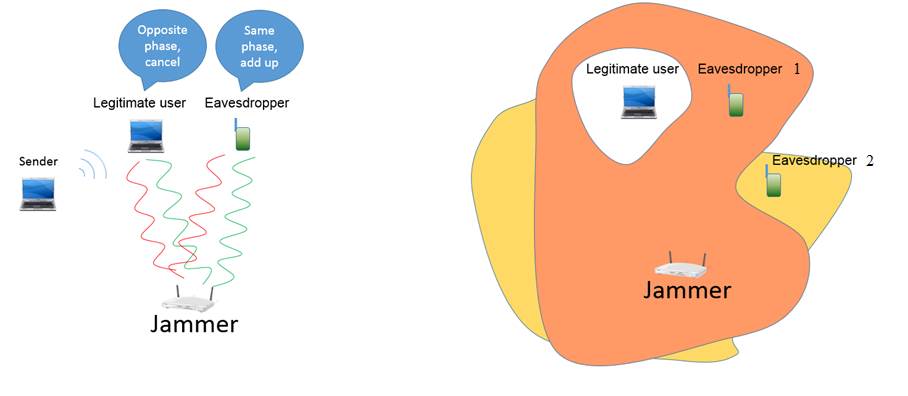
Privacy has become a major
concern in wireless networks, especially in networks with weak or no password
protection, such as some hotel Wi-Fi or airport Wi-Fi networks that have no or just
a common password.
One approach to improve the
security is to send friendly jamming signals to thwart the reception of the
eavesdropper. Basically, the jammer can send jamming signals that will maintain
significant power at the eavesdropper, but will cancel at the legitimate
receiver. This can be achieved, for example, by sending signals that add up
constructively at the eavesdropper but destructively at the legitimate receiver.
There are two main challenges
with friendly jamming. First, to maintain significant power at the eavesdropper
but not the legitimate receiver, the Channel State Information (CSI) of both
the eavesdropper and the legitimate receiver may be needed. However, although
the CSI of the legitimate receiver may be available, the eavesdropper is not
going to cooperate. Therefore, the friendly jamming technique must assume that
the CSI of the eavesdropper is unknown. Second, the jamming signal typically
cannot introduce enough errors to cover the entire packet when the jamming
signal is not very strong, mainly due to the use of error correction codes in
the system.
Our solution, jMax, solves these problems based on a simple idea. That
is, jMax uses multiple jamming vectors, i.e., parameters that will make sure that the legitimate
receiver does not receive any jamming power, in a round-robin manner. jMax works because while not all jamming vectors
are effective for any given eavesdropper,
where effective means to leave significant power, by carefully selecting
the set of jamming vectors, at least some
jamming vectors will be effective. As a result, the eavesdropper will be
guaranteed to receive some large jamming power during some part of the packet
reception. The jamming vectors used by jMax have proven
performance bounds to the optimal jamming signal power. jMax also uses an error amplifier, which
amplifies maybe just a few errors, which occurred during the high jamming power
period, into errors throughout the packet.
We collected real-world CSI
data with the Intel 5300 wireless card and use the Microsoft Sora Software-Defined Radio to process jammed data packets.
Our results show that jMax achieves significant gains
over other approaches, measured by the fraction of jammed packets.
Publication:
1. Z. Zhang and A. Mukherjee*, “Friendly channel-oblivious
jamming with error amplification for wireless networks,” in Proc.
of IEEE Infocom 2016,
San Francisco, USA, April 2016. Acceptance rate: 18%. 9 pages.
Slides:
Friendly Channel-Oblivious Jamming with
Error Amplification for Wireless Networks
|
L2Relay – A Faster Wi-Fi Range Extender Protocol |
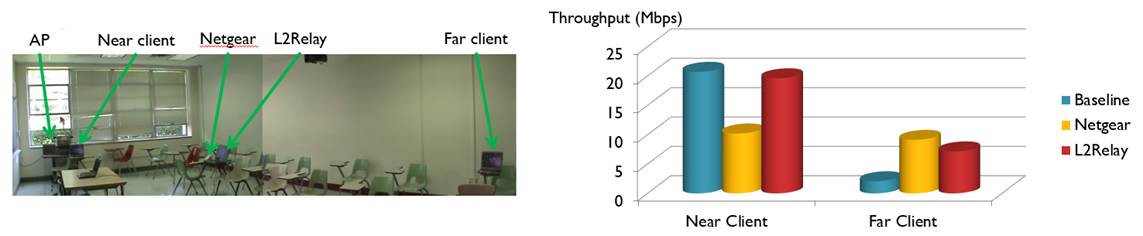
Wi-Fi is widely used today. It
is also well-known that Wi-Fi has a limited range, a problem that can be solved
to a degree by range extenders. However, a common consumer complaint about
Wi-Fi range extender is that it reduces the network speed, although it does
increase the network range. The root cause of this problem is that the range
extender repeats every packet, which is not needed for a near client that can
receive from the Access Point (AP) directly. For such clients, the signal from
the range extender actually congests the air and reduces the network speed.
We have developed a technology
called L2Relay that can solve this problem. The key idea of L2Relay is to repeat a packet only when it is highly
likely the packet has not been received correctly, which can be detected by the
absence of the acknowledgement that should follow a successful packet transmission.
While the idea is simple, many challenges must be overcome, such as link
quality estimation, rate selection, and distributed coordination among multiple
relayers, all under the constraint that the AP and
the client devices cannot be modified.
The main features of L2Relay
are:
·
L2Relay
can be incorporated into existing range extenders as a firmware upgrade and
boost their performance at no or little additional cost.
·
L2Relay
does not need any modifications to other devices in the network.
·
With
the help of L2Relay, the range extender will be able to make optimal decisions
for individual clients and will repeat packets only when needed. As a result,
the far client can still get service as usual, while the near client will not
see an unnecessary speed reduction.
We have implemented a prototype
L2Relay extender on a commercial wireless card (BCM4306) by modifying its
firmware. The prototype has been compared with a popular range extender on the
market (Netgear Universal Wi-Fi Range Extender WN3000RP-100NAS), and it was found
that L2Relay can double the network speed for the near client while achieving
similar speed for the far client.
Publication:
1. S. Zhou* and Z. Zhang, “L2Relay: Design and
implementation of a layer 2 Wi-Fi packet relay protocol,” in Proc. of IEEE ICNP, Gottingen, Germany,
October 2013. 10 pages. Acceptance rate:
18% (46/251).
Slides:
L2Relay: a Layer 2 Wi-Fi Packet Relay
Protocol
|
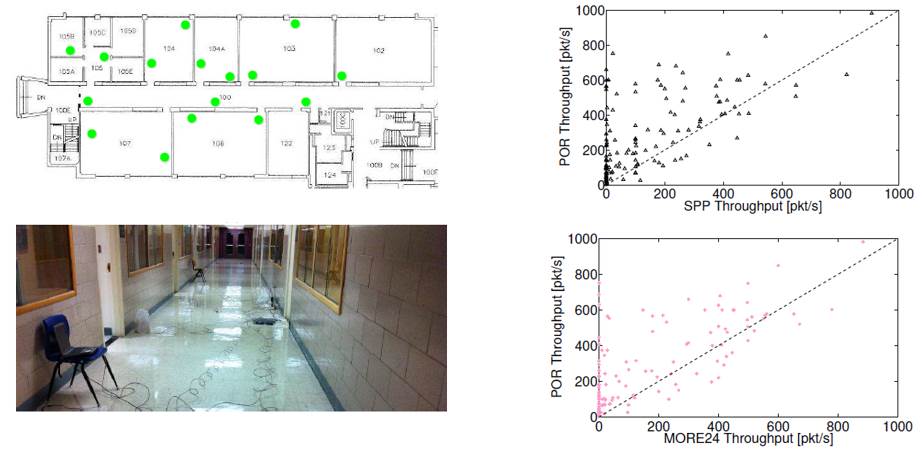
POR – Practical Opportunistic Routing for Wireless
Mesh Networks |
Our ACM Mobihoc 2013 paper describes POR, a
packet forwarding protocol for wireless mesh networks, where POR stands for Practical
Opportunistic Routing. In a wireless mesh network, wireless mesh routers are
deployed to forward data packets over wireless links hop by hop to the end
users; it is an attractive solution because it extends network coverage at low
cost. Opportunistic routing improves the performance of the network by
exploiting the overheard packets to reduce the number of transmissions.
The existing solutions for
wireless mesh network include the traditional routing protocols and academic
research prototypes adopting the opportunistic routing principle. However, they
either suffer low performance, or cannot work seamlessly with upper layer protocols
such as TCP, or have high complexity, or cannot support multiple data rates. To
elaborate:
·
Traditional
routing protocols forward packets following a fixed path. It cannot exploit the
packets that have been overheard, i.e., a node still has to transmit a packet
even when a downstream node has already received the packet by picking up the
wireless signal. As a result, the performance of traditional routing protocols
often cannot meet the need of high bandwidth applications.
·
There are many
academic research prototypes, such as ExOR, MORE,
MIXIT, Crelay, and SOAR, that employs the
opportunistic routing principle to improve the performance of network. With
opportunistic routing, a node will not transmit a packet if the downstream
nodes have obtained it due to overhearing. However, existing solutions may
require packet batching thus cannot work with upper layer protocols such as TCP
due to packet batching, or suffer high complexity and cannot support high data
rates, or can only work in a network with only one link data rate. As a result,
the existing academic research prototypes cannot be deployed in real-world
wireless mesh networks.
The main idea of POR simple. After a node receives a packet, it sets a
timer, and only forwards the packet if no feedbacks from the downstream nodes
have been received before the timer expires. Additionally, POR also
exploits partial packets and by transmitting only the corrupted parts in the
packet based on the feedback. It also includes mechanisms for multi-hop link
rate adaptation and path cost calculation to enable good path selection.
As a result, POR is the first
protocol that meets all the requirements for high-speed, multi-rate wireless
mesh networks, including:
·
running on
commodity Wi-Fi interface
·
requiring no
packet batching, therefore can work with TCP
·
low complexity
·
supporting multiple
link layer data rates
·
exploiting
partial packets
Therefore, it can be deployed
to improve the performance of real-world wireless mesh networks. We have
implemented a prototype of POR within the Click modular router and our
experiments in a 16-node wireless testbed confirm that POR achieves
significantly better performance than the compared protocols, i.e., the MIT MORE
and the traditional routing protocol with no opportunistic routing.
Publication:
1. W. Hu*, J. Xie* and Z. Zhang, “Practical opportunistic
routing in high-speed multi-rate wireless mesh networks,” in Proc. of ACM Mobihoc,
Bangalore, India, August 2013. 10 pages. Acceptance rate: 10.3% (24/234).
Slides:
Practical Opportunistic Routing in High-Speed Multi-Rate Wireless Mesh Networks
|
Software Partial Packet Recovery in Wi-Fi Networks |
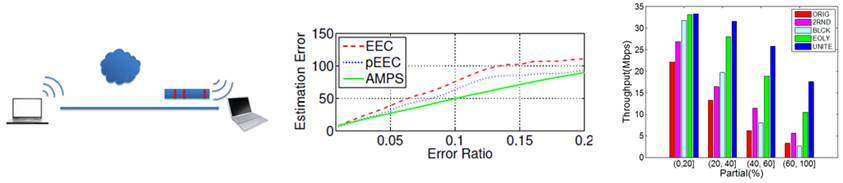
Our ACM Mobisys 2011 paper describes UNITE, a software partial packet recovery scheme for Wi-Fi networks. In a Wi-Fi link, a packet may be received correctly in most parts but contains just a few errors. Such packets are usually referred to as the partial packets; they will not pass the CRC check and will be discarded by the Wi-Fi protocol and retransmissions will be scheduled. We note that it makes much more sense to repair such packets instead of retransmitting them because the number of errors in such packets is usually very small. Partial packet recovery has been studied in recent years and significant gains over the original Wi-Fi protocol have been demonstrated. The existing repair methods include retransmitting the corrupted parts of the packet or correcting the errors with an error correction code.
We, in a sense, revisit this
problem due to the following motivations. First, the repair methods are not
mutually exclusive; a joint repair scheme may achieve better performance.
Second, we propose an error estimator referred to as AMPS, which can estimate
the number of errors in a packet and provide important information for partial
packet recovery. Third, the existing methods assume the CPU usage is not a
constraint, while our experiments show that the CPU usage can be very high in
many cases such that a recovery scheme that works under a CPU usage constraint
is needed.
UNITE employs multiple repair methods to provide best flexibility under
various scenarios. Different repair
methods have different pros and cons: retransmission does not consume CPU time
but is more vulnerable to random errors; error correction consumes CPU time but
is more resilient to random errors. A repair method may be ideal for one case
but not for others. By supporting multiple repair methods, UNITE is more
flexible than existing schemes which support only one repair method. In
addition, UNITE also supports a third repair method, referred to as the Target
Error Correction (TEC), which first locates the corrupted blocks and uses an
error correction code to correct the errors in the corrupted blocks. Compared
to the block-based retransmission, TEC requires less repair data because only
the parity bytes are transmitted which can be much smaller than the size of the
original data. Compared to the packet level error correction, TEC zooms in the
corrupted parts of the packet and requires less parity bytes and less CPU time
for decoding. In practice, TEC can recover a large percentage of packets
because many packets contain just a few errors.
UNITE uses AMPS as the error estimator to determine the number of
errors in a packet such that it is able to make intelligent decisions on packet
recovery. An error estimator can
roughly tell the number of errors in a packet which can be used to determine
the most efficient repair method. Error estimator was studied only very
recently and the other estimator is EEC (Efficient Error
Estimating Coding: Feasibility and Applications) which received the Best Paper
Award in ACM Sigcomm
2010. We use AMPS because it is
comparable with or better than EEC in every aspect. On performance, we did
a simulation comparison and found that AMPS has smaller estimation errors than
EEC. On overhead, AMPS requires an additional 8 bytes per packet while EEC
requires 36 bytes per packet when the packet size is 1500, the most common
packet size in Wi-Fi networks. On complexity, both AMPS and EEC can be
implemented according to a simple table lookup. AMPS achieves better
performance than EEC because it was developed according to the Maximum A Posteriori criteria while EEC is a simple algorithm.
UNITE is a practical packet recovery scheme because it checks its CPU usage and will not over-consume the CPU time. The decoding of the error correction code can take non-trivial time because such algorithms are highly complicated. Earlier papers, such as ZipTx (ZipTx: Harnessing Partial Packets in 802.11 Networks) which was published in ACM Mobicom 2008, argue that the CPU usage caused by the decoding algorithm is low. We note that the experiments in ZipTx were carried out on high end desktop machines; on devices with weaker CPU such as smartphones and tablets, the CPU usage will become a key constraint. We confirm with our experiments on a Toshiba laptop computer that the CPU usage can be very high under certain channel conditions. Therefore, UNITE takes a parameter from the system as the decoding time limit and uses an algorithm to select the best repair method to maximize the link throughput under the CPU time constraint.
UNITE is a software-only solution that can be
installed at the Access Point (AP) and the user devices running on commodity
wireless cards and bring immediate benefits. We implement UNITE and AMPS on the MadWifi
driver and our experiments confirm that UNITE achieves higher link throughput
than all existing methods while consuming CPU time under the specified
constraint. To date, UNITE is the state-of-the-art software partial packet
recover scheme.
Publications:
1. J. Xie*, W. Hu* and Z. Zhang, “Revisiting partial
packet recovery for 802.11 wireless LANs,” in Proc. of ACM Mobisys, Washington DC, USA,
June 2011. 12 pages. Acceptance rate:
17.7% (25 / 141). [accepted]
[ACM final]
2. J. Xie*, W. Hu* and Z. Zhang, “Efficient software partial
packet recovery in 802.11 wireless LANs,” IEEE Transactions on Computers, vol.
63, no. 10, pp. 2402-2415, 2014.
|
Multi-User Multiple-Input-Multiple-Output (MU-MIMO)
for Wi-Fi |

In our paper published in IEEE Infocom 2010,
we propose to use the Multi-User Multiple-Input- Multiple-Output (MU-MIMO) to
improve the Wi-Fi downlink throughput. We refer MU-MIMO on the downlink as
One-Sender-Multiple-Receiver (OSMR) for clarity because MU-MIMO can also be
used to refer to the uplink transmissions. With OSMR, the network downlink
throughput can potentially be increased by several times, because the Access
Point (AP) can send distinct data to multiple clients simultaneously.
We started to work on OSMR in
2008; prior to that, OSMR has been mainly studied with theoretical analysis and
simulations. Our focus was to apply OSMR in Wi-Fi networks which are typically
deployed indoors with highly dynamic traffic. In 2008, it was unclear whether
or not OSMR was applicable to Wi-Fi networks because the indoor wireless
channel characteristics for OSMR were not well understood; in addition, the problems
of scheduling OSMR transmissions under the dynamic Wi-Fi data traffic had not
been studied yet.
We were among the first to implement prototype OSMR transceivers and
conduct indoor OSMR experiments. Our
implementation was in C++ with GNU Software Defined Radio. Our experiments confirm that the indoor
wireless channel can be stable and usually contains sufficient degrees of
diversity to support OSMR.
We also study the problem of packet scheduling with OSMR. Basically, OSMR opportunities arise when the
wireless channel permits; however, as an OSMR transmission involves multiple
nodes, the AP may or may not have data to send to all nodes. The key challenge
of the problem is to cope with both the randomness in the wireless channel and
the randomness in the traffic. To this end, we first prove that the optimal
scheduling packet problem is NP-hard, and then propose a practical algorithm.
We conduct simulations with the
wireless channel traces collected with our GNU Software Defined Radio
implementation and the real traffic traces in Wi-Fi networks. Our simulation
result confirms the gain of OSMR; more importantly, it proves that the gain is determined to a large degree by the nature
of the traffic, which is a key distinction between our finding and the findings
in other papers which focus only on the wireless channel and assume constant or
saturated traffic, such as an ACM Mobicom 2010 paper (Design and Experimental
Evaluation of Multi-User Beamforming in Wireless LANs) published shortly after our paper. We used the
simulation for evaluation because the GNU Software Defined Radio is a physical
layer tool and does not efficiently support Medium Access Control layer
functions. Today, the collective efforts
from multiple research groups have convinced the protocol standardization
organizations to consider adopting MU-MIMO in the 802.11 protocol; the future
802.11ac will likely support MU-MIMO.
Publication
(journal version is under review after major revision):
1. Z.
Zhang, S. Bronson*, J. Xie*
and W. Hu*, “Employing the one-sender-multiple-receiver
technique in wireless LANs,” in Proc. of
IEEE Infocom, San Diego, USA, March 2010. 9
pages. Acceptance rate: 18 % (276 / 1575).
[paper]
2. Z.
Zhang, S. Bronson*, J. Xie*,
W. Hu*, “Employing
the one-sender-multiple-receiver technique in wireless LANs,” IEEE Transactions on Networking, vol.
21, no. 4, pp. 1243-1255, 2013.
|
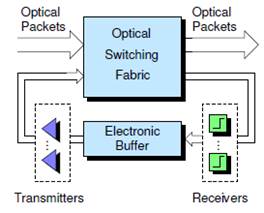
OpCut – High
Performance Optical Packet Switch (Collaborative Project) |
Optical technology will reshape
the interconnection network design for high performance computing systems
because of its huge capacity and relatively low power consumption. I have been
working on optical networks since my PhD and a major part of my PhD thesis is
about packet scheduling in optical networks.
I have been continuing this line of research since joining FSU.
We have been working on a
project on practical optical packet switching, which has been supported by NSF
since 2009. We propose a new switching architecture, called OpCut, which combines optical
switching with electronic buffering. OpCut is an
attractive solution for optical packet switching because practical optical
memory still does not exist and electronic memory is the only viable solution
for providing the buffering capacity needed by a switch. Prior to OpCut, IBM, Corning, and the US Department of Energy
started a project called OSMOSIS with the goal of
building an optical packet switch, which also uses electronic buffers. The core
difference between OpCut and OSMOSIS is that OpCut achieves lower packet latency, which is critical for
high performance computing applications where the latency should ideally be in
the order of microseconds.
The key feature of OpCut to achieve low
latency is that it allows an optical packet to cut-through the switch whenever
possible. That is, optical packets
will be directly transferred from the input side to the output side such that
packets experience only the propagation delay in most cases if the traffic load
is not excessively high. On the other hand, the OSMOSIS switch converts every
packet from the optical form to the electronic form, which introduces extra
latency as well as increasing the power consumption.
After we conceived the idea of OpCut, we did an initial performance analysis with a Markov
chain model, which was presented in IEEE
IPDPS 2009. We wrote the proposal based on our preliminary results and
submitted to NSF, which was funded in 2009. We have
been working on the OpCut project and our results
have been presented in two papers in IEEE
Infocom 2011. An extended version of one of the IEEE Infocom 2011
papers has been published in IEEE Journal
of Lightwave Technology. More journal papers are currently under
preparation.
One of the key challenges in the OpCut switch
is to maintain packet order, which we solve with a novel solution based on a
timestamp-based buffer. In the OpCut switch, if a packet cannot cut through, it is
converted to the electronic form and buffered in the middle nodes. When the
output ports are free, the middle nodes can send the buffered packets to the
output ports. Because the packets arrived at the same input port may be sent to
different middle nodes, the packet order may be disrupted. On the other hand,
upper layer protocols such as TCP depend on the assumption that the network
switches do not send packets out of order in most cases. The packet ordering
problem in the OpCut switch is similar to the packet
ordering problem in the two-stage switch; however, the existing solutions for
the two-stage switches are either too complicated or cannot be implemented in
an optical switch. Our solution is to use a buffer indexed by the packet
timestamp and is very simple in nature. Basically, packets are written to the
buffer according to their timestamps. The output ports keep track of packet
information and only request for packets at the head of the flows. If an output
port can receive a packet, it can send the lower bits of the timestamp to the
middle node which can locate the packet in constant time.
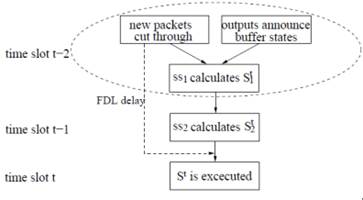
We study the packet scheduling problem with a pipelined scheduler to
reduce the length of a time slot. The
performance of the OpCut switch, similar to the
input-buffered switch, is to a large extent constrained by the efficiency of
the scheduling algorithm which determines which packet can be sent from the
input port to the output port and which packet has to be buffered. Advanced
algorithms will lead to better performance; however, the complexity of the
algorithm is under the constraint that the algorithm must converge to a solution
in a time slot, i.e., the time to send a data block or a cell, because a
decision is needed in every time slot. We propose to adopt a divide-and-conquer
approach by breaking down the scheduling problem into smaller problems where
each small problem is finished in a time slot. Basically, we introduce multiple
sub-schedulers, each taking the partial schedule calculated by the
sub-scheduler of lower order and augmenting the schedule with more packet
transmissions. The advantage of such pipelined scheduler is that advanced
scheduling algorithm can be used without increasing the length of the time
slot. We rigorously prove that duplicate scheduling, i.e., multiple
sub-schedulers scheduling the same packet, does not occur with our algorithm
when two sub-schedulers are used. We also propose a technique called “adaptive
pipelining” to reduce the packet latency when the traffic load is low.
Basically, when the traffic is low, the scheduling problem is simple and fewer
sub-schedulers may suffice such that the packets may experience less delay.
This work was first presented in IEEE Infocom 2011 and an extended version has been published
in IEEE Journal of Lightwave Technology.
We study the packet scheduling problems when there are multiple wavelengths
per optical fiber. The capacity of an
optical packet switching network is improved when the bandwidth of an optical
fiber is better utilized with multiple wavelengths carrying packets in
parallel. The packet scheduling problem with multiple wavelengths is even more
challenging than with a single wavelength, because multiple packets may arrive
an input fiber at one time slot and the orders of such packets must be
maintained. We prove that the optimal scheduling problem is NP-hard by reducing
the Set Packing problem to the scheduling problem. We further prove that the
scheduling problem cannot be approximated within a constant factor. Therefore,
we propose a set of practical scheduling algorithms and our simulations show
that they achieve good performance in typical conditions. This work was first
presented in IEEE Infocom
2011 and an extended journal version has been published in IEEE Transactions on Communications.
Publications:
1. L. Liu, Z. Zhang and Y. Yang, “In-order packet scheduling in optical switch with wavelength division multiplexing and electronic buffer,” IEEE Transactions on Communications, vol. 62, no. 6, pp. 1983-1994, June 2014.
2.
L. Liu, Z.
Zhang and Y. Yang, “Pipelining packet scheduling in a low latency optical
packet switch,” IEEE Journal of Lightwave
Technology, vol. 30, no. 12, pp. 1869-1881, June 2012. [accepted] [IEEE
final]
3.
Z. Zhang and
Y. Yang, “Performance analysis of optical packet switches enhanced with
electronic buffering,” in Proc. of IEEE
IPDPS, Rome, Italy, May 2009. 9 pages. Acceptance rate: 22.7 % (100 / 440).
[paper]
4.
L. Liu, Z. Zhang and Y. Yang, “Packet scheduling in a low-latency optical
switch with wavelength division multiplexing and electronic buffer,” in Proc. of IEEE Infocom,
Shanghai, China, April 2011. 9 pages. Acceptance rate: 15.96% (291 / 1823). [accepted]
[IEEE
final]
5.
L. Liu, Z. Zhang and Y. Yang, “Pipelining packet scheduling in a low
latency optical packet switch,” in Proc.
of IEEE Infocom, Shanghai, China, April 2011. 9
pages. Acceptance rate: 15.96% (291 /
1823). [accepted] [IEEE
final]
|
Bandwidth Puzzle – Securing the Incentives in P2P
Networks (Collaborative Project) |
Peer-to-Peer (P2P) technology has been widely deployed; it has been reported that over 65% of the Internet traffic is P2P traffic. Our papers on the incentive schemes in p2p networks solve a critical problem: why is a peer willing to contribute its resources and serve other peers, as serving other peers means the consumptions of network bandwidth, CPU cycles, and battery life? A selfish peer may choose not to serve any peer; the system will fail if it allows such peers to get free rides.
The key challenge in designing
a good incentive scheme is that the peers may collude. A naïve approach, for
example, is to collect data transfer logs from the nodes and give higher
priorities to peers who have uploaded more data to other peers. This naïve
approach will fail because such logs can be forged; Alice may send a report to
the system claiming that she has uploaded a large file to Bob while actually
she has not. It is also useless to confirm this claim with Bob because Bob may
be a friend of Alice and may lie to the system such that Alice may get free
credits from the system.
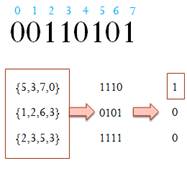
The key breakthrough to this problem is the puzzle challenge scheme
first described in our ICISS 2009
paper. The idea is to challenge all peers simultaneously with puzzles and
require everyone to send back the answers of the puzzles before a timeout. The puzzle has the key properties that 1) it takes
time to solve the puzzle and 2) the puzzles can be solved only if the peer has
the content that it claims to possess. Therefore, a peer cannot solve the
puzzle if it does not have the content; neither can its friends help in solving
the puzzle because the friends have to solve their own puzzles before the
timeout. As a result, the fake transactions can be detected.
The puzzle solution is major contribution because it is the first real
solution to the secure incentive problem. Prior to that, no solutions existed. The free rider can potentially get
service without doing any work, which has been demonstrated by several research
papers on popular p2p networks such as BitTorrent.
The puzzle challenge scheme can be adopted in such p2p networks and improve the
security of the incentive mechanisms.
Another major contribution is the performance bound I proved for the
puzzle. The theoretical proof of the
bound appears in the April 2012 issue of IEEE
Transactions on Information Forensics
& Security. The bound
gives the expected number of bits the peers must upload to be able to solve the
puzzles with a certain probability. Such a bound is needed because it gives an
assurance to the system on the expected outcomes after applying the puzzle. The first ICISS 2009
paper provided a weaker bound; the new bound is much tighter because it can be
approached asymptotically by a practical strategy. The
major challenge in proving the bound is that the adversaries may collude and
adopt any algorithm. The bound must be established against the optimal
algorithm; however, the optimal algorithm is unknown due to the complexity of
the puzzle challenging scheme. The breakthrough is to adopt an indirect proof
technique, i.e., introducing an intermediate system which is easier to reason
about and is close to the real system in performance. Basically, I first prove
the difference between the intermediate system and the real system, and then
prove the bound for the intermediate system which is combined with the
difference to establish the bound for the real system.
Publications: