
Peixiang Zhao
Department of Computer Science
Florida State University Office: 361 James J. Love Building
Address: 1017 Academic Way
Tallahassee, Florida 32306
(Map)
Email: pzhao [AT] fsu [DOT] edu
FSU Calendar
Research Interest
- Data and network science
- Database systems
- Data/Graph mining
- Data-intensive computing
Research Group
- Current Students
- Bowen Li (Doctoral student, Fall 2019 - )
- Ashwati Nair (Doctoral student, Fall 2021 - )
- Alumni
- Jiyang Bai (Ph.D., Spring 2024 ): Huawei Technologies
- Yongjiang Liang (Ph.D., Fall 2021): Amazon Robotics, Arlington, VA
- Esra Akbas (Ph.D., Fall 2018): Assistant Professor in CS @ Georgia State University, GA
- Xibo Chen (Master student, Fall 2021): Florida A&M University (FAMU)
- Hussain Islam (Master student, Summer 2021): MathWorks
- Andrew Berg (Master student, Summer 2019): U.S. SUGAR
- Adam Stallard (Master student, Summer 2017): Amazon
- Yilin Wang (Master student, Summer 2017): Oracle
- Shashank Golla (Master student, Summer 2016): Fauna
- Nkemdirim Dockery (Master student, Summer 2015): RPI
- David Lafontant (Master student, Spring 2015): Tata
- Menghe Zhang (Master student, Fall 2014)
Research Summary
Modern science and technology have witnessed in the past decade an explosive growth of networked systems giving rise to a vast ocean of data with completely transformed scale, structure, and complexity. These networked data are voluminous, fine-grained, heterogeneous, dynamic, and, without loss of generality, can naturally be modeled and interpreted as big graphs. While these graphs have revolutionized the way we create, model, and disseminate complex networked data, their sheer sizes and unique complexity have rendered them extremely hard to manage, costly to ingest, and complicated to analyze.
My research centers around data and network sciences, database systems, data mining, and Big Data systems. Specifically, I have been striving to (1) understand the theoretical foundations and algorithmic principles underpinning the generation, organization, function, and evolution of large-scale networked systems, and (2) design and develop efficient, cost-effective, and scalable algorithms and computational tools for modeling, managing, querying, and mining big graphs in a wide spectrum of conceptual, physical, technological, ecological, and societal applications in today's networked world.
Selected Research Projects
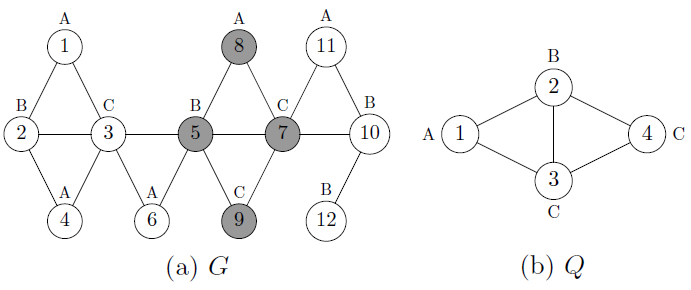 Graph Query Modeling, Processing, and Optimization. The dominance of graphs
in real-world applications asks for efficient access methods and graph-aware querying functionalities that
enable exploration and utilization of big graphs in a way far beyond the conventional, SQL-based solutions.
At the core of many graph-based computational tasks lies a fundamental and critical graph querying primitive,
the objective of which is to search as output all the relevant (sub-)graphs, either exactly or approximately,
from big graphs for a user-specified, graph-structured query.
We have proposed a series of efficient and cost-effective graph indexing solutions
to support high-performance subgraph query processing and optimization in big graphs.
Graph Query Modeling, Processing, and Optimization. The dominance of graphs
in real-world applications asks for efficient access methods and graph-aware querying functionalities that
enable exploration and utilization of big graphs in a way far beyond the conventional, SQL-based solutions.
At the core of many graph-based computational tasks lies a fundamental and critical graph querying primitive,
the objective of which is to search as output all the relevant (sub-)graphs, either exactly or approximately,
from big graphs for a user-specified, graph-structured query.
We have proposed a series of efficient and cost-effective graph indexing solutions
to support high-performance subgraph query processing and optimization in big graphs.
Related publications: VLDB'22, ICDE'19, ICDE'17, KDD'12, SIGMOD'11, VLDB'10, VLDB'07
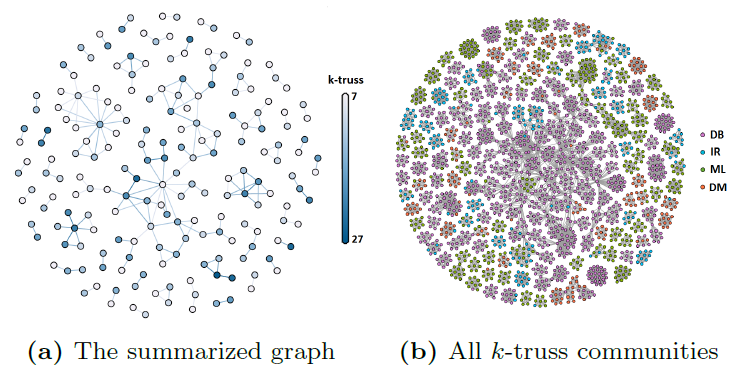 Mining, Learning, and Summarizing Big Graphs.
In a wide array of graph mining, learning, and computational tasks, a key observation has been recognized that oftentimes, only a small fraction of graphs, or certain facets/dimensions of graph data, are mission-relevant. As a result, an exhaustive
exploration of entire graph data turns out to be overkill, thus inevitably incurring a large amount of wasteful computation.
To realize this vision, we have proposed a series of graph summarization methods to optimize graph mining and learning in real-world big graphs.
Mining, Learning, and Summarizing Big Graphs.
In a wide array of graph mining, learning, and computational tasks, a key observation has been recognized that oftentimes, only a small fraction of graphs, or certain facets/dimensions of graph data, are mission-relevant. As a result, an exhaustive
exploration of entire graph data turns out to be overkill, thus inevitably incurring a large amount of wasteful computation.
To realize this vision, we have proposed a series of graph summarization methods to optimize graph mining and learning in real-world big graphs.
Related publications: VLDB'24, ICDE'20, VLDB'17, CIKM'15, CIKM'09
 Scalable Computation in Dynamic Graph Streams.
Real-world big graphs are not static but dynamically evolving all the time in extremely fast speed. As a result, they are often modeled as graph streams where individual edges of the underlying big graph are received and updated in a form of a data stream. Due in particular to the dynamic and transient nature, we cannot explicitly materialize graph streams in memory, or even on disks, for repeated exploration and computation. We have proposed a series of cost-effective graph sketches, and constant-time or sub-linear approximation algorithms for efficient graph analytics with theoretically guaranteed accuracy and performance in big graph streams.
Scalable Computation in Dynamic Graph Streams.
Real-world big graphs are not static but dynamically evolving all the time in extremely fast speed. As a result, they are often modeled as graph streams where individual edges of the underlying big graph are received and updated in a form of a data stream. Due in particular to the dynamic and transient nature, we cannot explicitly materialize graph streams in memory, or even on disks, for repeated exploration and computation. We have proposed a series of cost-effective graph sketches, and constant-time or sub-linear approximation algorithms for efficient graph analytics with theoretically guaranteed accuracy and performance in big graph streams.
Related publications: CIKM'25, ICDE'16a, ICDE'16b, VLDB'12