| COP4610: Operating Systems & Concurrent Programming | up ↑ |
These notes started with an outline of the contents of Chapter 4 in Stallings' OS text. I fleshed them out with an example and some more details about Solaris and Linux threads.
These two aspects are independent, and so can be separated:
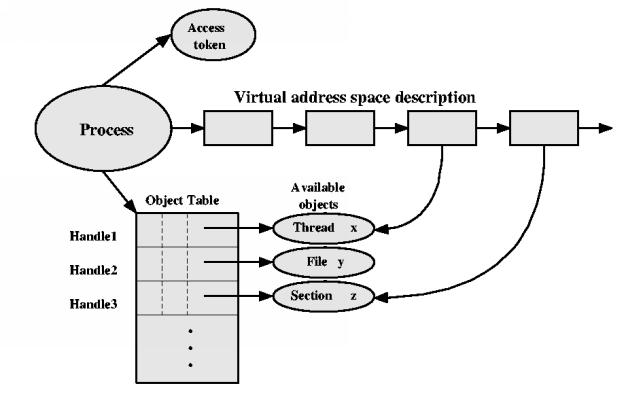
Process = Resources + Thread
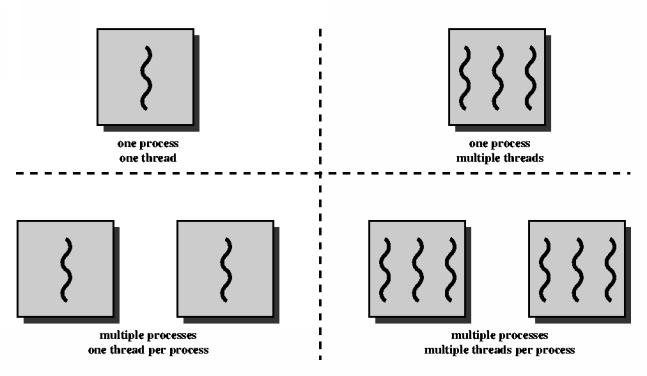
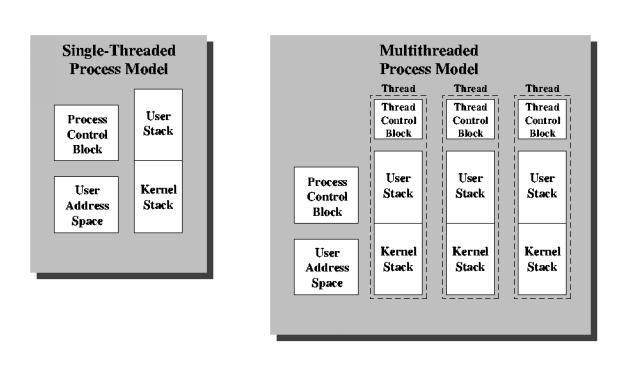
Having answered the question of why we might want more than one thread per process, make certain you remember why we need threads, and why we need processes.
Since one main reason multithreading was introduced is to make better use of hardware parallelism, this is a good point to discuss multiprocessor operating systems. However, that is not the only reason threads may be useful.
Of these types of parallel architectures, the MIMD seems to have been most widely adopted. That is probably because people found it more natural to write software for this model. In particular, the SMP architecture is now quite common, especially in the form of systems with dual processors.
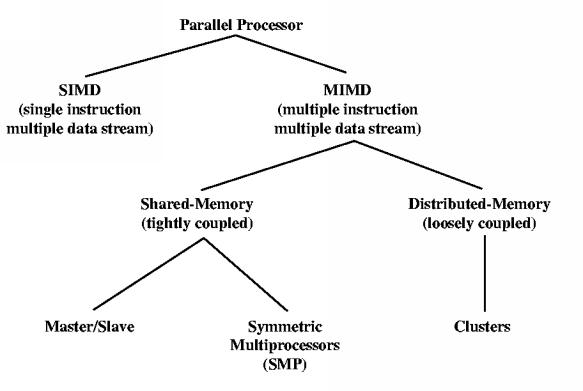
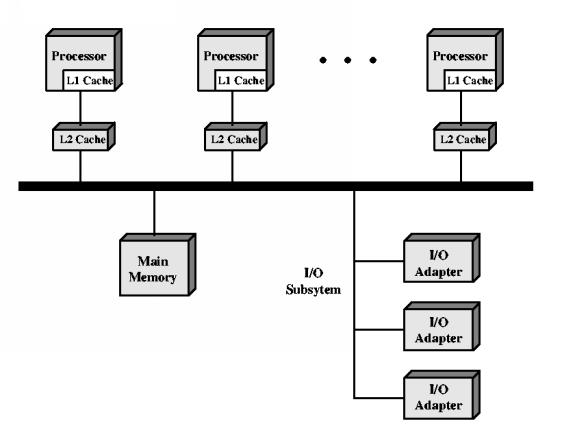
The existence of true parallelism complicates virtually all aspects of the operating system design. Optimal CPU scheduling turns out to be much harder. Algorithms that are optimal for a single-CPU system can be very bad for an SMP system. Optimal multiprocessor scheduling is NP-hard. Synchronization is harder for SMP systems. The interrupt-masking technique no longer works, since we have truly parallel execution. Memory management may be complicated by considerations of CPU-local versus shared memory. Fault tolerance becomes critical, because with more CPU's there is much higher probability of a single-CPU failure, and because people may ask for the system to continue operating as long as one CPU is working.
I would rather avopid using the term "spawn", as in the textbook, for thread creation. The term "spawn" has been traditionally used in Unix for process creation. For example, the following is taken from the combined POSIX/Unix 98 Specifications:
The posix_spawn() and posix_spawnp() functions shall create a new process (child process) from the specified process image. The new process image shall be constructed from a regular executable file called the new process image file.
All OS actions are triggered by some event. There are two kinds of such triggering events:
Events that cause the thread to change state can be characterized similarly:
In general, writing software that can deal with asynchronous events is harder than writing software that only has to deal with synchronous events. The main problem with asynchronous event handling is that the event handler cannot assume much about what else is going on at the time it executes.
To see how hard this is, suppose the grader for this course did not tell you when your programming assignment would be collected. Suppose the grader had permission to access your files, and simply picked an arbitrary time to fetch a copy of your program from your home directory. How could you be sure that the version graded is one that is working? Suppose you kept two versions in different directories, and only copied from your working version to the directory where the grader would pick things up when you thought you had a good, working version. It could still be that the grader collects the program while you are copying, and so gets part of one version and part of the next version. It might not even be compilable!
For this reason, system designers generally keep asynchronous event handler very simple. They usually just capture the minimum information necessary to record the event, in a simple data structure in memory, and let the rest of the processing be done synchronously, by a thread or process that is responsible for reading from that data structure and processing the event.
There are two approaches to thread implementation
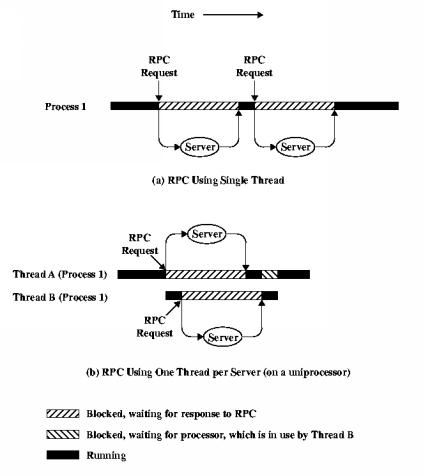
This demonstrates the usefulness of single-thread blocking.
See also the explanation in the text of how Adobe Pagemaker uses threads to improve user responsiveness by decoupling asynchronous activities.
There are also two approaches to thread scheduling
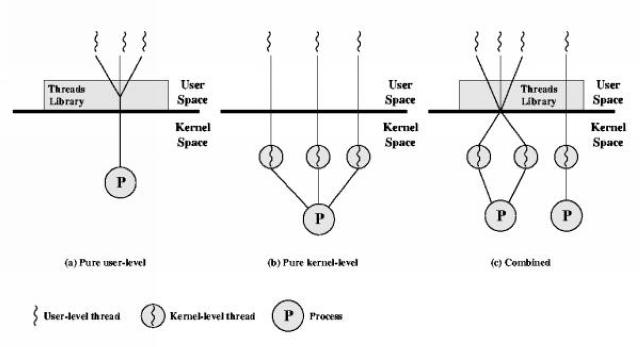
To see one of the advantages of a combined implementation strategy, look at the benchmark results comparing Solaris (combined) and Linux (kernel) threads, reported further below in these notes.
However, after the publication of those results, Solaris updates dropped the two-level model in favor of a single-level model, with one kernel thread per user thread. It seems that the industry practice is converging toward a single implementation model, namely:
It is too bad that the players could not have agreed upon this before the POSIX thread standard was approved, since it would have resulted in a cleaner and more portable API.
| Operation | User-Level Threads | Kernel-Level Threads | Processes |
|---|---|---|---|
| null fork | 34 us | 948 us | 11,300 us |
| signal-wait | 37 us | 441 us | 1,840 us |
The null fork operation consists of creating and destroying a new thread to execute a procedure that does nothing but return. This is intended to measure the overhead of thread creation.
The signal-wait operation consists of signaling another blocked thread to go, and then blocking in turn. This is intended to measure the overhead of thread synchronization.
Support the POSIX API & semanics, with extensions
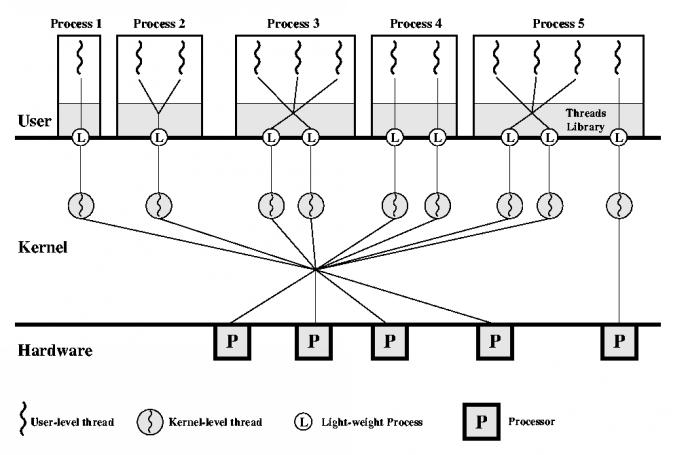
This combined implementation model gives the maximum flexibility to users, to configure their applications to take advantage of both logical and physical parallelism. However, making good use of this flexibility requires the programmer to have quite a bit of knowledge of both the application and the hardware it will run on, and to exercise quite a bit of judgement.
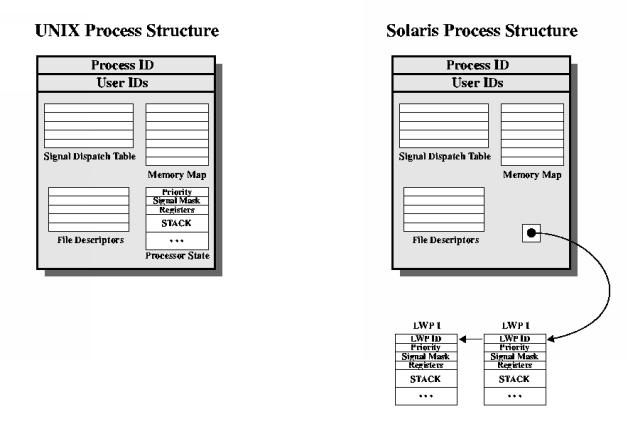
Today, Unix means more than one thing. There was one original Unix operating system, but it evolved, and the name was then applied to many different operating system implementations. Unix is a registered trademark, originally owned by ATT, but currently managed by The Open Group. The name is applied to several generations of operating system specifications, and it can be applied to any operating system product for with The Open Group has licensed use of the name. Since Solaris and Linux both currently attempt to implement the same Unix specifications, they can both be called Unix operating systems in this sense. However, some books use the name Unix is a more restrictive sense, to mean a specific historical operating system, apparently Unix System V Release 4, which was a milestone in the development of ATT Bell Laboratories original thread of Unix systems.
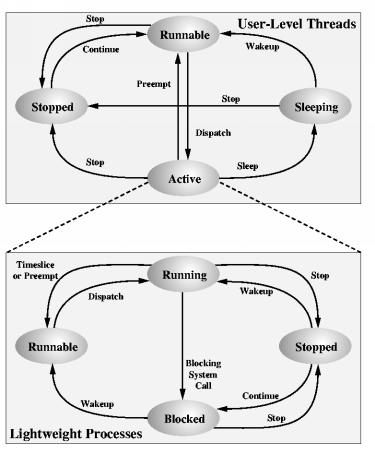
When one of these events occurs, the LWP that was assigned to the thread executes a user-level thread dispatcher routine, which looks for another runnable ULT.
This is in contrast to situations where the system blocks the LWP itself, in a kernel call. In that case, the LWP is tied up, and cannot switch to another ULT. For this reason, we need multiple LWP's, to prevent whole-process blocking.
Support the POSIX threads API, but not the semantics.
Linux threads are implemented by the clone() system call, which creates a new task with has a copy of the attributes of the current process.
The child (clone) task shares with the parent (cloned) task:
It also ends up sharing some other attributes that POSIX and the SUS say should be replicated for each thread.
There is a new Native POSIX Thread Library implementation, called "NPTL", which is supposed to be much closer to the POSIX model.
The following abstract classes of information are attributes of a Linux process that are contained in the task_struct data structure. Each Linux thread has its own copy of this structure.
Sunlike Solaris/SunOS Linux was not designed from the bottom up to support threads. The clone() call duplicates most of the process state, which includes the attributes listed here.
Some of these attributes are shared by all the threads in the process. Some are specific to the thread. Can you guess which are which?
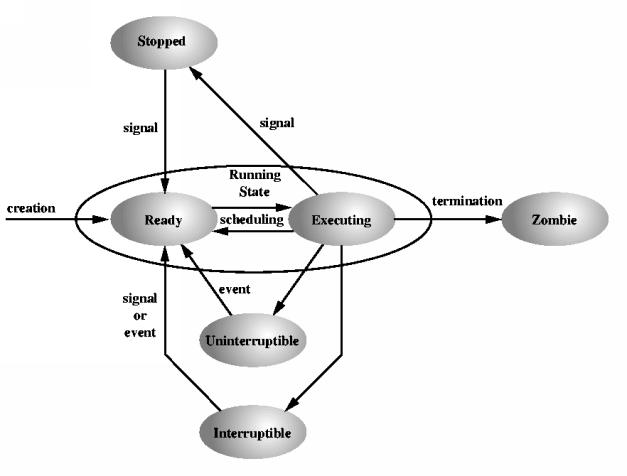
The process state tells whether the task is
These states are defined in sched.h as:
#define TASK_RUNNING 0 #define TASK_INTERRUPTIBLE 1 #define TASK_UNINTERRUPTIBLE 2 #define TASK_ZOMBIE 4 #define TASK_STOPPED 8
See file null_fork.c. It is an example of a program similar to that used to derive the performance comparison results mentioned above.
Besides illustrating the obvious performance difference between process creation and thread creation, this example can serve as a review of the Unix process API, an introduction to the Unix thread API, and a side-by-side comparision of the two. Therefore, it is worth looking at the example in detail.
You should read through this code, and make sure you understand it. The system calls for process creation and termination should already be familiar, from the examples we covered previously.
The are separate notes on the POSIX threads API provide more information on these and other POSIX thread system service calls.
There are several different Unix clock functions, of varying precision. We use this simple one to estimate the amount of time used by the program for certain segments of its execution. We really would like to know the amount of CPU time, but there is not yet a well standardized way of getting that information from the system, so we approximate what we want by taking the elapsed real time. If the time interval is short enough that there is no process switch, this will be essentially the same as the CPU time used by the process.
------------------------------ system clock ticks per second = 1000000 microseconds per clock tick = 1 ----------processes----------- iterations = 1000 number of iterations = 1000 elapsed time = 6060000 ticks elapsed time = 6060000 us avg time per iteration = 6060 us -----------threads------------ number of iterations = 1000 elapsed time = 110000 ticks elapsed time = 110000 us avg time per iteration = 110 us ------------------------------ performance ratio = 55 ------------------------------ system clock ticks per second = 1000000 microseconds per clock tick = 1 ----------processes----------- iterations = 1000 number of iterations = 1000 elapsed time = 6390000 ticks elapsed time = 6390000 us avg time per iteration = 6390 us -----------threads------------ number of iterations = 1000 elapsed time = 110000 ticks elapsed time = 110000 us avg time per iteration = 110 us ------------------------------ performance ratio = 58 ------------------------------ system clock ticks per second = 1000000 microseconds per clock tick = 1 ----------processes----------- iterations = 1000 number of iterations = 1000 elapsed time = 6620000 ticks elapsed time = 6620000 us avg time per iteration = 6620 us -----------threads------------ number of iterations = 1000 elapsed time = 100000 ticks elapsed time = 100000 us avg time per iteration = 100 us ------------------------------ performance ratio = 66
This output from three runs of null_fork on a machine with four 450 MHz Ultrasparc 2 processors running the Solaris 8 operating system.
Here is some newer data, from the same machine running Solaris 9.
------------------------------ system clock ticks per second = 1000000 microseconds per clock tick = 1 ----------processes----------- number of iterations = 1000 elapsed time = 2610000 ticks elapsed time = 2610000 us avg time per iteration = 2610 us -----------threads------------ number of iterations = 1000 elapsed time = 120000 ticks elapsed time = 120000 us avg time per iteration = 120 us ------------------------------ performance ratio = 21
The ratio is not quite so good. That is probably due to Solaris phasing out the multi-level thread implementation, in favor of 1:1 mapping of user threads to kernel-schedulable threads (LWPs).
------------------------------ system clock ticks per second = 1000000 nanoseconds per clock tick = 1 ----------processes----------- iterations = 1000 number of iterations = 1000 elapsed time = 220000 ticks elapsed time = 220000 us avg time per iteration = 220 us -----------threads------------ number of iterations = 1000 elapsed time = 50000 ticks elapsed time = 50000 us avg time per iteration = 50 us ------------------------------ performance ratio = 4 ------------------------------ system clock ticks per second = 1000000 nanoseconds per clock tick = 1 ----------processes----------- iterations = 1000 number of iterations = 1000 elapsed time = 180000 ticks elapsed time = 180000 us avg time per iteration = 180 us -----------threads------------ number of iterations = 1000 elapsed time = 60000 ticks elapsed time = 60000 us avg time per iteration = 60 us ------------------------------ performance ratio = 3 ------------------------------ system clock ticks per second = 1000000 nanoseconds per clock tick = 1 ----------processes----------- iterations = 1000 number of iterations = 1000 elapsed time = 190000 ticks elapsed time = 190000 us avg time per iteration = 190 us -----------threads------------ number of iterations = 1000 elapsed time = 40000 ticks elapsed time = 40000 us avg time per iteration = 40 us ------------------------------ performance ratio = 4
This output is from three runs of null_fork on a machine with two 550 MHz Pentium III processor running the Red Hat 7.2 Gnu/Linux operating system.
| OS/Threads | Processor Speed | Processes | Threads | Ratio |
|---|---|---|---|---|
| Linux 2.4.7 | 550 MHz | 220 us | 50 us | 4:1 |
| Linux 2.4.7 | 550 MHz | 180 us | 60 us | 3:1 |
| Linux 2.4.7 | 550 MHz | 190 us | 40 us | 4:1 |
| Solaris 8 | 450 MHz | 6060 us | 110 us | 55:1 |
| Solaris 8 | 450 MHz | 6390 us | 110 us | 58:1 |
| Solaris 8 | 450 MHz | 6620 us | 100 us | 66:1 |
The table shows, in nanoseconds, some average process creation/termination times reported by null_fork when run on two different operating systems. Since the results vary from one execution to the next, three examples are given. The times shown are in microseconds.
Observe that the ratio of process creation time to thread creation time (rightmost column) is about 4:1 for Linux threads and about 60:1 for Solaris threads. Taking the cost of creating a process as a norm, this says the cost of creating a Solaris thread is about 1/15 that of creating a Linux thread. That difference must be mainly due Linux threads being kernel threads. Creation of a new Linux thread is a kernel operation and it involves much of the same work as creation of a new process. In contrast, Solaris threads are implemented via a combination of kernel-level threads (LWPs) and user-level threads. The benchmark that generated these numbers only required the creation of a user-level thread, so we are seeing the difference in cost between user-level and kernel-level thread creation. This difference is one reason Solaris makes use of two levels. Where user-level threads will do, they clearly are more efficient.
| T. P. Baker. ($Id) |