| COP4610: Operating Systems & Concurrent Programming | up ↑ |
We will address all of these questions. Before we begin, though, it is important to review the context in which the mutual exclusion comes up. That is concurrent execution.
The need for mutual exclusion comes with concurrency.
There are several kinds of concurrent execution:
All these kinds of concurrency have some need for mutual exclusion. The mechanisms for achieving it differ. What works for one will not work for the others.
The four kinds of concurrent execution listed above correspond to both layers of system development and levels of difficulty. Generally, the implementation of mutual exclusion becomes more complex at each successive layer, and depends on having a working solution at the layer below. We will look at the first three in some detail before we are done, and perhaps touch lightly on the fourth.
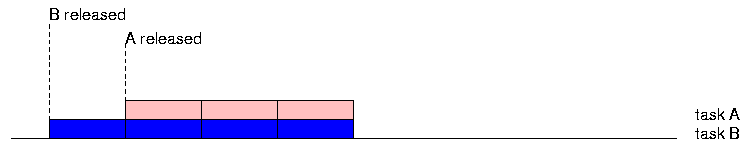
The most extreme form of concurrency is truly parallel execution, utilizing processors. In a multiprocessor system it is possible that two threads of control execute, literally, in parallel.
This is illustrated in the form of a Gantt chart, in which the time intervals during which each of two theads of control is shown by a horizontal colored bar.
All of this discussion applies to conccurent threads of execution, which may be called different things in different systems. They are called "tasks" in the chart. We might just as well have called them threads (or single-threaded processes). The term "task" is used here in honor of the built-in concurrent programming abstraction of the Ada programming language. Linux also uses the term task for kernel-level threads of control.
Task B (blue) is "released" (meaning it enters the ready state) first. Task A (pink) is released some time later. The release of A does not interrupt the execution of B because each task has its own processor.
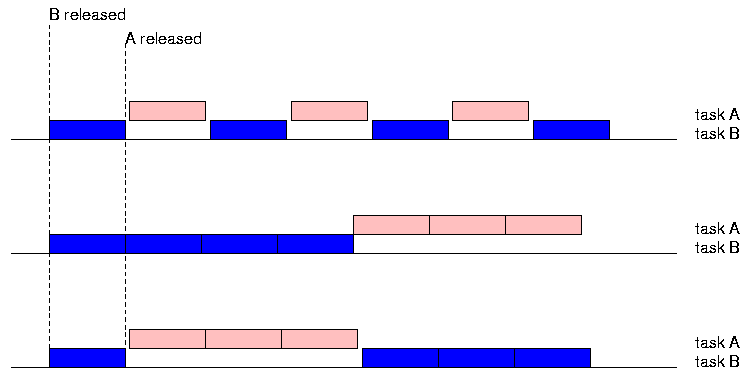
If there is only one processor, the operating system will need to arrange for the tasks to share the processor. The OS scheduler decide when each task gets to execute. Depending on the CPU scheduling policy of the operating system, many different interleavings are possible.
The figure shows three different interleavings, which happen to correspond to two basic scheduling policies often adopted by operating sytems. These are both preemptive policies, in which the CPU scheduler may interrupt the execution of one task and give control of the CPU to another task.
The first one is an example of round-robin time-sliced scheduling. CPU time is allocated to each task in slices of a fixed size, calls the scheduling quantum. The operating system implements this form of scheduling using a hardware timer, which interrupts the CPU periodically. The timer interrupt handler calls the CPU scheduler. Time-sliced round-robin scheduling allows both tasks a "fair" share of the CPU time. They both proceed approximately as if in parallel.
The second two examples are of priority-based run-until-blocked scheduling. The difference is in which of the two tasks has the higher priority.
In the first example, task B has the higher priority. Because it has higher priority, it is not interrupted when task A is released. Task A only executes when task B blocks or is suspended.
In the second example, task B has the lower priority. Because it has lower priority, it is interrupted when task A is released. Task A then executes until it blocks or is suspended, at which point task B resumes execution.
Priority-based preemptive scheduling is used for real-time systems. A real-time system is characterized by having timing requirements, generally imposed by the need to synchronize the actions of the computer system with events in the real world. For example the computer may be responsible for controlling a piece of machinery, such as an engine or the controls of an airplane. Failure to complete a computation at the required time may result in catastrophic failure of the controlled machinery, with possibly dire consequences.
By giving tasks with near deadlines higher priority, the application programmer tells the system they are more urgent. The system complies by executing them ahead of other tasks of lower priority. This is "unfair", but necessary for correct functioning of the application.
We will discuss CPU scheduling, including real-time scheduling, in more detail later. It is a very fascinating subject, which many computer scientists and industrial engineers have spent a long time studying.
The examples illustrate preemption of the CPU from one task by another. They assume that it is generally safe to preempt a task and take away the CPU from it, so long as the CPU is given back to the task some time later. (This is not always be true, but it true often enough tht we will accept it as true for now.)
The CPU is just one of the resources that a task (process or thread) may need in order to execute. Other resources include memory, access to shared data objects in memory, and access to peripheral hardware devices. A little thought will reveal that some of these cannot be preempted safely.
The term mutual exclusion is applied to a condition in a
resouce is protected in such a way that whenever a task (thread or
process) obtains
The following example involves concurrent increment and decrement operations on an integer variable that is is shared between two threads.
volatile int M = 0;
void * A () {
...
M = M + 1;
...
}
void * B () {
...
M = M - 1;
...
}
Suppose procedures A and B may be executed concurrently by different tasks. One increments the value of the variable M and the other decrements it. The designers of the software intend that the value of M be the difference between the number of calls that have been made to A and the number of calls that have been made to B. We will see that, without mutual exclusion on M, the code will fail to achieve the intent.
In order to analyze this example we will need to agree on the level at which we will consider operations to be atomic.
The notion of atomicity is relatated to that of mutual exclusion, but the two concepts axre distinct.
The need for mutual exclusion comes from the interactions between concurrent tasks. Tasks interact through resources they share. On a digital computer system, all operations can be broken into discrete steps. This means that if we break each interaction down we will eventually reach some level at which it cannot be broken down further. We can then analyze the interaction in terms of possible interleavings of these atomic steps.
Literally, the adjective atomic means that an object cannot be divided into smaller units. In reality, we know that this property is relative. The particles physicists call atoms are considered indivisible for the purposes of chemistry, but when we study nuclear physics we learn that atoms can be split into component parts.
The same applies to atomicity in computing. When we talk about an operation being atomic, it is in only atomic with respect to the other members of some set of operations. We must always pay attention to this, that we not assume a stronger kind of atomicity than we actually have.
As we progress through the text and the course, we will encounter different levels of atomicity. At some points, we will be looking at operations whose atomicity depends on the hardware. At other points, we will look at operations whose atomicity depends on the operating system's software. At other points, the atomicity may be determined by application-level software.
Actual code, when compiled for SPARC architecture:
sethi %hi(M), %o1 or %o1, %lo(M), %o0 sethi %hi(M), %o2 or %o2, %lo(M), %o1 ld [%o1], %o2 add %o2, 1, %o1 st %o1, [%o0]
On a simplified abstract machine:
Ra = M; /* load register Ra from memory location of M */ Ra++; /* increment register */ M = Ra; /* store value in register back to memory */
The assignment statement M = M + 1
will be translated into some sequence of machine instructions
by the compiler. An example from an actual computation
is shown, for the SPARC instruction set. It is clear from
this that the assignment statement is not implemented
in an atomic fashion. In particular, a hardware interrupt could
interrupt the execution between any two instructions and
call the CPU scheduler, allowing another task to execute.
Moreover, if the code is run on an SMP, individual instructions
could execute in parallel on different processors.
For the purposes of analyzing the example, we consider a simplified abstract machine, in which individual memory fetch and store operations are implemented atomically by the hardware, but other operations can be interleaved arbitrarily (even run in parallel, if we have an SMP architecture).
In this abstract model, the assignment statement is implemented by a load, an increment, and a store.
Smiilarly, the assignments statement M = M - 1
is implemented by a load, a decrement, and a store.
We will look at different ways in which these might be interleaved if executed concurrently by two different tasks.
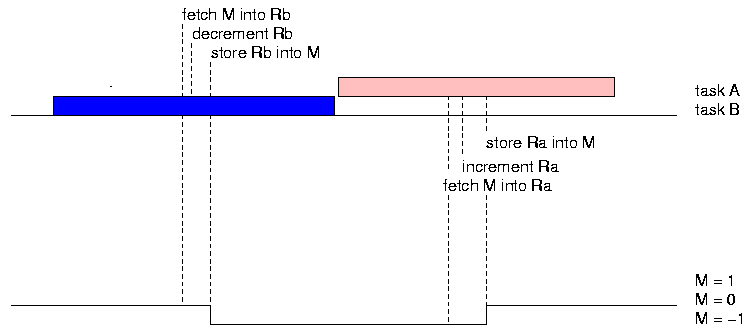
The Gantt chart shows the task executing procedure A in pink and the task executing procedure B in blue. The timings of the fetch, increment/decrement, and store operations are indicated by dashed vertical lines. The value of the variable M is graphed below the task bars. It starts out at zero, drops to -1 when B executes, and then goes back up to zero when A executes.
The code has the intended effect. The changes in the value of M by the two calls cancel one another out.
If there is no interleaving, the code has the intened effect.
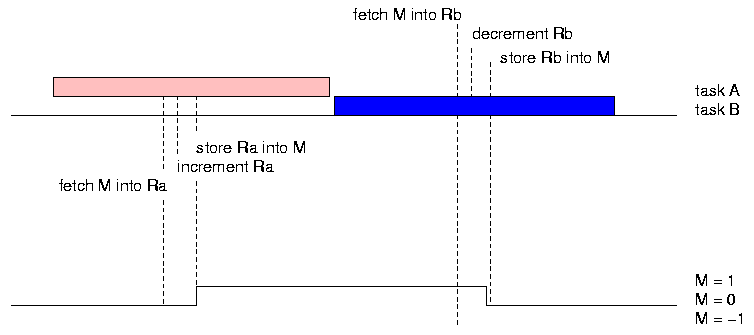
Which task executes first does not matter. The code still has the intended effect.
So long as there is no interleaving, the order in which the tasks executes makes no differece. After one call to each of A and B, the value of M is back to zero.
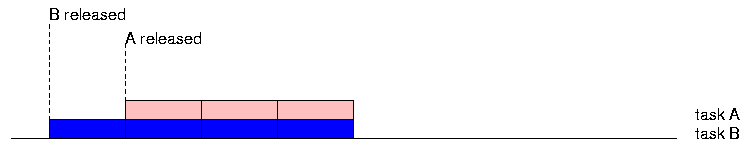
With parallel or interleaved execution, what happens?
We have a race between tasks A and B.
The effect of the execution depends on who "wins" the race.
Even supposing we have interleaved execution and the primitive memory fetch and store operations are atomic, the outcome depends on the particular interleaving of the operations.
We will look in detail at two of the (many) ways this interleaving can cause an unintended effect. For simplicity, consider a single processor, on which the operating system interleaves the execution of two tasks.
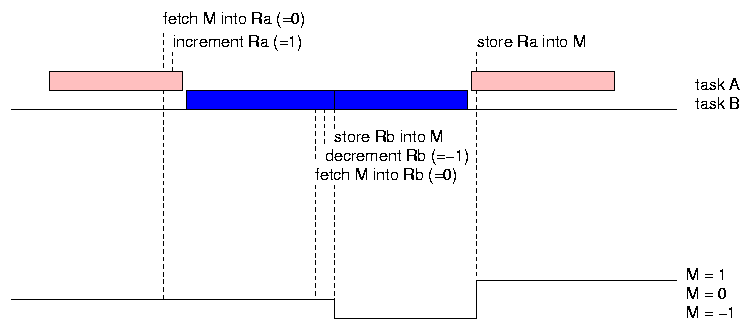
In this case, the execution of A is preempted by B between the register-increment and the store. B then succeeds in decrementing the memory copy of M, but when A resumes it stores the value it had in its register, wiping out the record of the intervening call to B. The final value of M is 1 instead of zero.
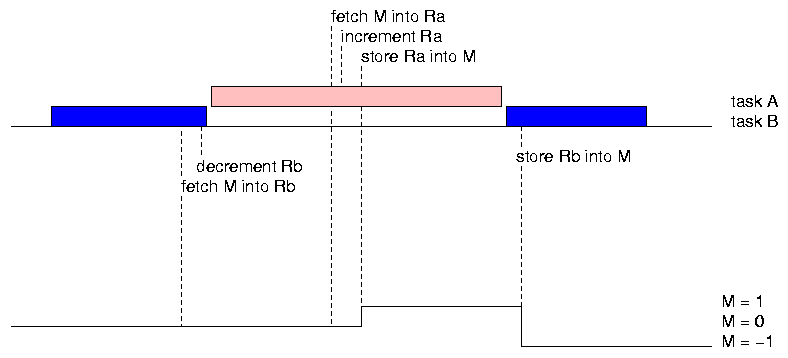
The same kind of thing can happen if A is allowed to preempt B.
It should be clear from these examples that when we program with multiple threads of control sharing variables we must be very careful. The examples are not contrived. In actual practice, without careful programming and some help from the operating system, such mishaps will inevitably occur.
When they do occur, they are especially troublesome, because they are hard to reproduce. Since the effect of the execution is timing-dependent, they may execute correctly most of the time, and when problems occur they may be very hard to isolate. The debugging process is made extremely difficult by the fact that the bug cannot be reproduced. In particular, the adding of output statements or the use of a debugging tool is likely to slow execution down to the point that everything appears to work correctly.
Since the main reason for introducing multithreaded processes is to allow shared access to the same virtual memory, any implementation of threads must provide a way for applications to safely update shared variables. For POSIX threads (and most other systems with threads), the mechanisms provided are mutexes and so-called condition variables (really a misnomer, since they do not represent conditions in the usual sense of the word, and are not variables in the normal sense).
A mutex is a type of memory object that is used for synchronization. It has two states: Locked and Unlocked. supports two operations that are of interest to us, which we will call Lock and Unlock. The Lock operation blocks the mutex until
The mutex Lock and Unlock operations must be implemented atomically (with respect to other operations on the same mutex) by the operating system.
Do not be misled by attempting to relate mutexes too closely to semaphores, or by the use of the name mutex in the examples in some texts as the name of a binary semaphore that is used to achieve mutual exclusion. A mutex is not the same thing as a binary semaphore. When you are trying to understand mutexes (and condition variables), it is best to just forget about semaphores.
pthread_mutex_t My_Mutex; ... pthread_mutex_lock (&My_Mutex); ... critical section ... pthread_mutex_unlock (&My_Mutex);
Mutexes are like to only be supported for use between threads within a single process.
This example is simplified. It does not check for error codes.
A region of code that is only executed while holding exclusive access to some resource is called a critical section with respect to that resource.
There may be more than one critical section (e.g., in different subprograms) for a given resource. Mutual exclusion requires that no two threads be able to execute concurrently within critical sections for the same resource. Once one thread enters a critical section for that resource, no other thread may enter until that thread leaves the critical section.
In the example code above, the resource is the mutex object My_Mutex. The name of the Lock and Unlock operations for POSIX mutexes are pthread_mutex_lock() and pthread_mutex_unlock(). The code between the calls pthread_mutex_lock(&My_Mutex) and pthread_mutex_unlock(&My_Mutex) is protected from concurrent execution by other threads, as as all other sections of code protected by lock-unlock pairs for the same mutex object.<
We must always take care to remember that a section of code is a critical section relative to some specific resource. For example, if we have two different mutex object, M1 and M2, we can have one thread executing within a critical section of M1 while another thread executes concurrently within a critical section of M2.
pthread_mutex_t mymutex;
void * A {
pthread_mutex_lock (&mymutex);
M = M + 1;
pthread_mutex_unlock (&mymutex);
}
void * B {
pthread_mutex_lock (&mymutex);
M = M - 1;
pthread_mutex_unlock (&mymutex);
}
The procedures A and B from the increment-decrement example, have been modified so that the increment and decrement operations on M are protected by a mutex.
See what happens now to one of our problem cases.
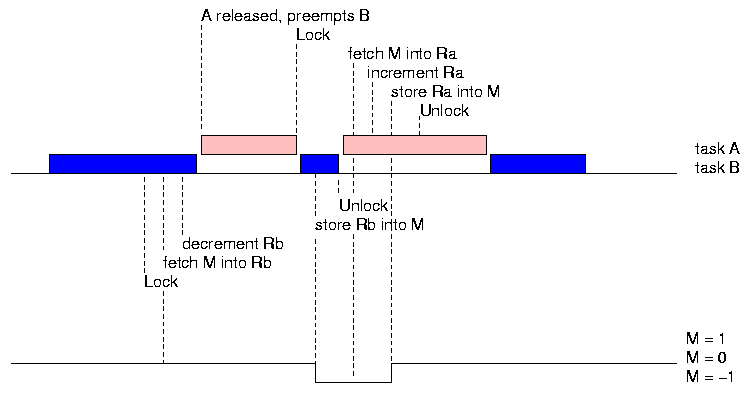
Suppose A tries to preempt B between the in-register decrement and the store operation. It preempts, but when it gets to the Lock operation it is blocked, because B holds the lock on the mutex. Task A stays blocked until task B has resumed execution and unlocked the mutex that protects M. Then, A can resume and operate on M. The effect is as intended. The increment and decrement operations are now atomic with respect to one another.
Notice that we have used atomicity implemented by the system for operations on the mutex mymutex in order to implement atomic updates to the application variable M.
This is they way things always are. The solutions to a problem at higher levels depends on the problem having been solved at a lower level (usually by someone else). It is important to keep your levels straight. The implementation of mechanisms at each level must depend only on lower level mechanisms. Thus, for example, the operating systems implementation of mutexes must rely on something more primitive than a mutex.
Ultimately, all operating system mechanisms rely on hardware mechanisms. The hardware mechanisms are also layered. At some level, one relies on the mechanisms, apparently put in place by God, that make the physical world work.
The following models a transaction that transfers an amount of money from one bank account to another.
void transfer (int amount, volatile long *from_account, volatile long *to_account) {
*to_account = *to_account + amount;
*from_account = *from_account - amount;
}
void * thread_1 (void *arg) {
...
transfer (10, &B, &A);
...
}
void * thread_1 (void *arg) {
...
transfer (10, &A, &B);
...
}
This generalizes the previous example slightly. There are now two variables that need protection. The invariant is the total amount of money that is split between the two variables. A full program containing this code is located in the file sharing_memory.c. We look at this program and some variants of it, below.
All of these examples are worth reading. In class, we go over just the first few of them, line by line, then run them and look at the output. The following slides and notes capture some of the main points.
The file sharing_memory.html contains the same code as sharing_memory.c, but includes HTML links to explanations of some of the features introduced by this example.
The program is intended to demonstrate that a program can really get into trouble if it contains several threads that can update the same memory object concurrently, without any provision for mutual exclusion.
There are two threads: (1) the main program's initial thread; (2) a thread created by the main program. One thread moves "money" from the account of A to the account of B, and the other thread moves "money" in the other direction. If the system works correctly, the combined amount of money in both accounts should be a constant. After each transaction, the thread that did the transaction calls the subprogram check_consistency() to see whether the combined amount has changed. If this consistency check fails, the process is terminated with exit status -1. Otherwise, the two threads go on executing until a maximum time limit is reached.
The time limit is implemented using the Unix alarm() function.
This function tells the system to generate a SIGALRM signal
after a specified number of seconds have passed. In this
case, the call is alarm (10);, meaning the alarm signal
should be generated in 10 seconds.
If the alarm signal is not handled, the process will be terminated by it. We want the process to terminate, but we would like to have a chance to write out a few lines of output first. Therefore, we attach a signal handler function to the SIGALARM signal. This is done using the sigaction() system call:
sigaction (SIGALRM, NULL, &act); act.sa_handler = handler; sigaction (SIGALRM, &act, NULL);
The first call fetches a structure describing the old action in place for signal SIGALARM. The assignment statement changes the handler component. The second call to sigaction swaps in the modified signal action. After that, whenever SIGALARM is generated for this process, the function handler() will be called.
If you look at the function handler() you will see that it just does some output, and then terminates the process.
void handler (int sig) {
fprintf (stderr, "exiting due to signal %d\n", sig);
fprintf (stderr, "count_1 = %ld10 count_2 = %ld10\n", count_1, count_2);
exit (-1);
}
A somewhat more detailed explanation of signals and signal handlers is provide in the notes on Signals.
Observe that the exit() function will kill all of the threads when it terminates the process. (Some problems have been reported in the past with Linux threads, that threads may be left running after the main program terminates. I have not seen that behavior so far this term. I hope that means the newer releases of Linux have fixed this bug.)
Executing sharing_memory.c produced the following output:
*** LOSS OF CONSISTENCY *** main: A = 49997390010 B = 50002611010 TOTAL-(A+B) = -3010 count_1 = 401710 count_2 = 110
What happened?
It should be fairly obvious that an apparent loss of consistency was detected, before the ten second timeout expired.
Note that the sources of inconsistency are not limited to the transactions alone. Because the consistency-check is also performed concurrently with the updates, it may be that the consistency checker gets values of A and B that straddle a transaction (e.g., the value of A before the transaction and the value of B after the transaction).
We have already discussed briefly the concept of reentrancy, and the use of alarm() with sigaction() to implement a process-level timout.
The word volatile indicates that the compiler should assume that this variable may be modified by a concurrent thread of control. In particular, it should not do any optimizations of loads and stored based on local analysis of the flow of control. This concept, and its importance in concurrent programming with shared variables, is explained in the separate note on Volatility.
The call pthread_setconcurrency (2); suggests to the implementation that we would like to have at least two kernel-level threads. This helps us to get more parallelism if we have an SMP.
pthread_mutex_lock (&M);
transfer (10, &B, &A);
check_consistency ();
pthread_mutex_unlock (&M);
The correct way to implement the transactions is as critical sections, protected by a mutex, as shown above. The complete code is in the file sharing_memory_safe.c. You may prefer to look at the file sharing_memory_safe.html, which contains the same code as sharing_memory_safe.c, but includes HTML links to explanations of some of the features introduced by this example.
Look at the section on mutexes in the notes on POSIX threads, or click on the individual links above for more explanation of the POSIX mutex API.
We now add locking around the code that updates the shared variables.
pthread_mutex_lock (&M);
transfer (10, &A, &B);
check_consistency ();
pthread_mutex_unlock (&M);
Executing sharing_memory_safe.c now produces the following output:
exiting due to signal 14 count_1 = 981553610 count_2 = 929906210
This indicates that both threads ran a long time, and were eventually killed by the alarm signal.
The mutex-protected version, sharing_memory_safe, did not run into any inconsistency, and so was terminated by the 10 second alarm.
If a thread tries do hold more than one mutex at a time, a problem known as deadlock can develop. In deadlock a set of threads becomes locked in a "deadly embrace" of wait-for relationships, which can never be resolved nondestructively.
pthread_mutex_lock (&mutex_B);
pthread_mutex_lock (&mutex_A);
transfer (10, &A, &B);
pthread_mutex_unlock (&mutex_B);
pthread_mutex_unlock (&mutex_A);
Suppose someone decided it is "elegant" to use a separate mutex to protect each shared variable, and so defined a mutex for A and a mutex for B. To do a joint transaction on A and B would require holding both locks at once, as shown in code above.
The program sharing_memory_deadlock.c uses two mutexes, in the way shown above.
Executing it produced the following output:
exiting due to signal 14 count_1 = 710 count_2 = 110
Why are the counts lower than the previous example?
The values of count_1 and count_2 are very low, compared to the previous example. Someone familiar with deadlock would guess that both threads stoped executing after less than a thousand transaction, because of deadlock. The deadlock was finally broken when the alarm signal terminated the process.
The diagram shows how the two threads in memory_sharing_deadlock.c can lock up.
Observe that the deadlock could not happen if the order of locking were the same in both threads. That is one of the standard ways of preventing deadlock.
What good reason might there be for using more than one lock?
A good reason for using multiple locks is to improve concurrency, by reducing contention for locks between processes. For example, if we have 100 objects accessed by two threads, all protected by one lock, the probability will be high that a thread will need that one lock, find that it is held by the other thread, and block. If we have 100 individual locks, and each thread only uses two of them at at time, the probability of a thread finding the lock it needs is held by another thread is greatly reduced.
(Can you apply combinatoric reasoning to figure out more precisely how much it is reduced? Suppose the probability of one thread interrupting the critical section of another thread is some constant. With one lock, the probability of conflict is that same constant. With a thread randomly choosing two out of 100 locks, the odds that Thread 2 will interrupt a critical section and choose one of the same two locks as Thread 1 are reduced by a factor of (1/98+1/97).)
See sharing_memory_ordered.c for an example of how to avoid deadlock with two mutexes.
We will look at deadlock in more detail in the Chapter 6.
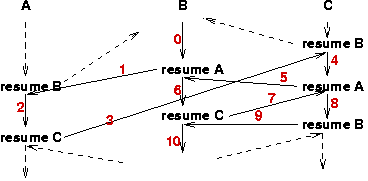
One of the earliest forms of concurrent programming is the use of coroutines.
The heart of the coroutine abstraction is the resume abstraction. This is a sort of variation and add-on to the subprogram call abstraction.
With a normal subprogram call, execution is transferred to the beginning of the subprogram and proceeds until the suprogram returns, at which point the call is over and execution resumes at the instruction following the subprogram call. Each call results in creation of a subprogram activation, which persists until return from the subprogram, at which point the data structure representing the execution context of that subprogram activation (the activation record) is deallocated and made available for reuse.
In the coroutine abstraction, a subprogram call is allowed to resume execution of another subprogram (coroutine) without deletion of the subprogram call's activation record. If a coroutine A executes the operation resume(B) it causes control to return to the point in coroutine B where B last executed a resume operation.
Coroutines interleave their execution explicitly, using calls to resume. Some people classify this as a form of concurrent execution, because each coroutine can be viewed as a logically distince thread of control, and because the interleaving is similar to the interleaving of execution that is necessary when several concurrent processes or threads are executed on a shared processor.
The big difference with coroutines is that the interleaving is non-preemptive. A coroutine can be certain that no other coroutine will be interleaved with it, until the coroutine calls resume.
Because coroutines are scheduled nonpreemptively, mutual exclusion is enforced implicity. Therefore, we will not address them further in the discussion of mutual exclusion.
| T. P. Baker. ($Id) |